
The discourse analyzer evaluates the semantic representations of the sentences of the text, derives statistical information from them about frequency and relevance of terms and ontological topics, extracts the event frames from the representations and all kind of so-called discourse referents, annotates them by ontological classifications and computes referential chains between them, where ontological constraints about the discourse referents are exploited on the one hand and extrapolated on the other by inheriting them along the referential lines detected.
An excerpt may look as follows:
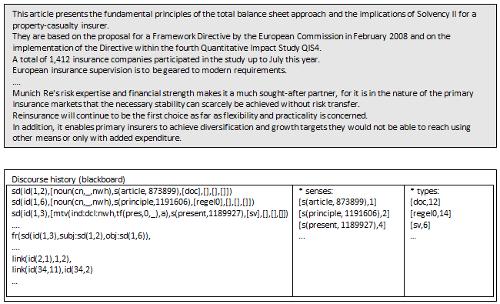
The discourse history is a kind of blackboard which stores the relevant semantic information of the sentences of the text. This is:
- information about the discourse referents, i.e. the objects, persons, events talked about in the text (for instance in sentence 1 at position 2 the word ‘article’ has been used which introduces a discourse referent, identified by id(1,2), for a document)
- information about predicate argument structures, in particular event frames (for instance the event for ‘present’ with its roles filled by ‘article’ and ‘principles’ is such a frame)
- information about the referential chains (for instance ‘they in sentence 2, position 1, id(2,1), refers to ‘article’, id(1,2))
From this, statistical evaluations can be made. For instance, the absolute frequency of the readings of the words used in the text can be computed or the weights of semantic types used. As in addition morphological, syntactic and structural semantic information is available, very precise text classifications can be calculated, sentiment analysis can be carried out and other things.
Please contact us for further information, prices and individual advice by sending us an e-mail.