
The semantic annotator condenses the syntactic structure to the semantically relevant nodes and the respective relations, adds ontological knowledge to the nodes if available and does a number of structural modifications if this is needed in order to provide a representation which is more ‘homomorphic’ with respect to the deep semantic structuring of the sentence (for instance, it resolves some types of ellipsis, etc.).
The results, so-called semantic dependency trees, are compact encodings of so-called underspecified discourse representation structures which can be constructed from the trees by using the semantic information of the lexical entries as can be derived from the lexicon via the identifiers annotated to the nodes. On the basis of these representations intra- and inter-sentential references can be computed, scope relations between partial representations can be introduced, weakened or strengthened, depending on the contextual information exploited.
A particular advantage of this representation level is the compact representation of event descriptions and states where auxiliary structures of the syntactic level (like do-support etc.) are compressed to just one node for the event or state which dominates the corresponding verb roles.
In the output below (which has been computed from the result of the syntactic annotator in the previous section) there is just one node from the verb complex (present).
Instead of the auxiliary structure the features connected to this node inform about mood, tense and voice (mtv): The event has been introduced by the main clause (i.e. it is independent, ind), in declarative mood (dcl – not a question or an imperative), without a wh-element (as in a relative clause, etc.), on tense level past, by a perfective tense (1 = perf) and unspecified progressive form (X1 = variable = unspecified). The voice was active (a), not passive (p) or resultative passive (rp).
Some of the nodes show semantic (ontological) type information: sheet and article are doc(uments), law is a gesetz0 (i.e. the semantic type corresponding to the word law).
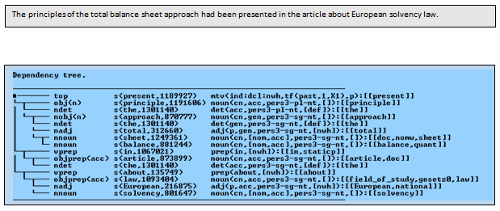
Semantic dependency trees help to do statistical semantic evaluations of the text, compute referential links, do named entity recognition and gather information about named entities, and carry out a number of other textual evaluations like text classification, summarizing etc. This is done by the Discourse Analyzer.
Please contact us for further information, prices and individual advice by sending us an e-mail.